

rl with an llm grader
What's the next step after having solid llm evals? The answer is making your models better.

In my piece about evaluating llms, I came across this image that really stuck out to me:
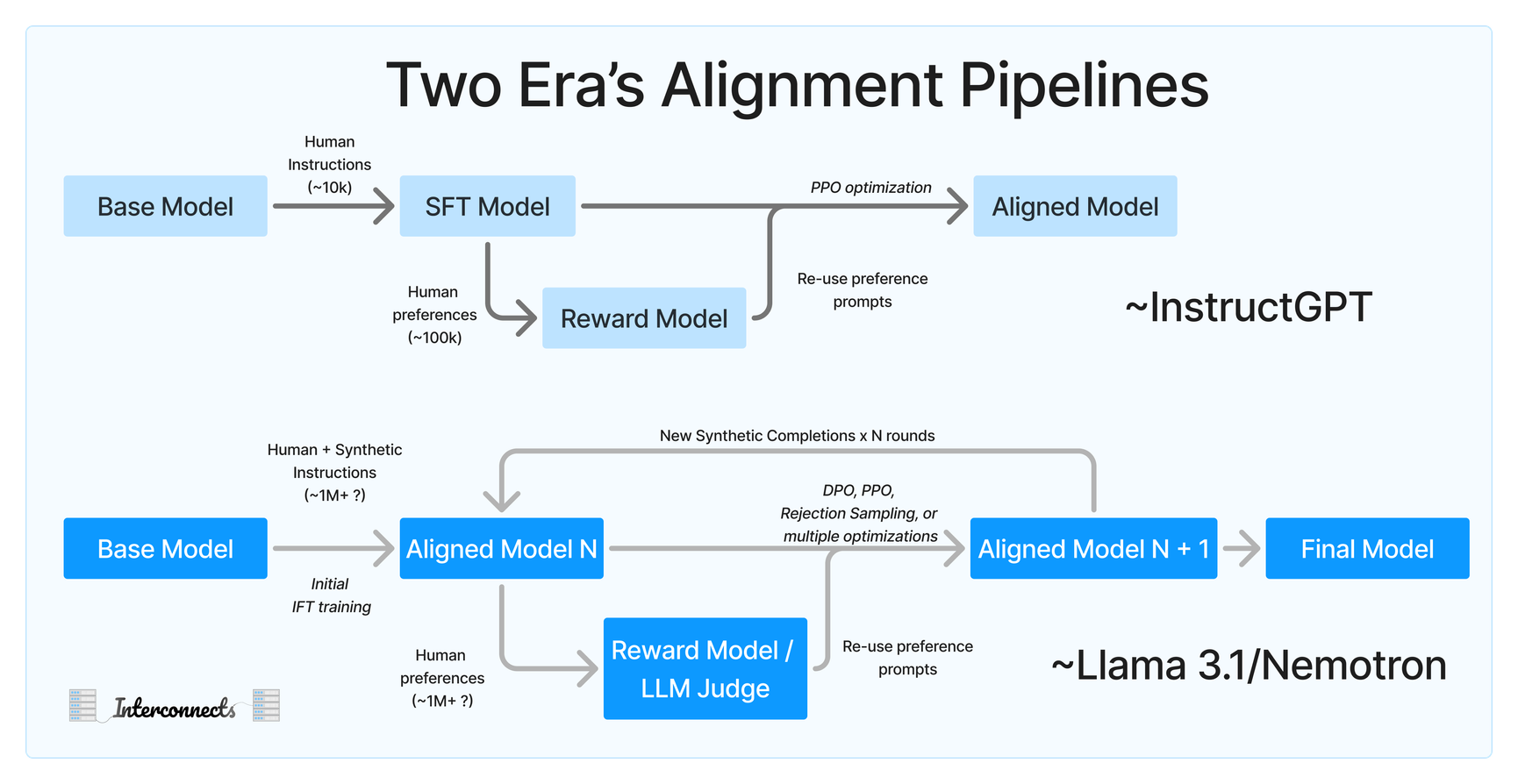
I wanted to do a post on running an rl processs on a base model using an LLM judge as reward to see if this was any good. For this we will create a simple model that functions as a magic 8 ball, randomly producing a result from the Magic 8 Ball answer list shortened to yes, no, and maybe. I wanted a task that reflected the opaqueness of a summarization task, but that we could train a way simpler model for. For training data we will use this list of good question 8 ball questions with targets to a random output from the magic 8 lists1.
We will then fine tune our model on a set of “graded” data with “human” preferences. To accomplish this, we will take a similar dataset but with targets produced from a larger model, like BERT, stating what it thinks a human would want to hear. We will then run PPO on our model with our aligned feedback, and see how our models end weights update. If I had more time, I would prompt am LLM model like llama on a specific output, like saying yes more often, to showcase how we can manipulate a simple model. This will have to do for now though.
First though, let’s start with why even RL train a model in the first place.
Why?
There are two big why questions here. Why rl train a base model in the first place? And why use an llm as a judge?
Obviously it depends on your use case, but there is a “last mile” issue with LLMs.
For very large language models, they have a lot of language intelligence floating around, but may not know how to be a “helpful chatbot” like chat gpt. RL is how we take the intelligence, and focus it in on the specific problem.
This same problem happens one step after though, when we attempt to use a model like ChatGPT for even more specific use cases. For example, if you are summarizing baseball games, there will only be so many baseball game summaries online. Even worse, the llm’s summaries may be better than what is available, making pre-training data not efficient. This is where RL training from feedback comes in even though we aren’t working at OpenAI.
The big question is why not just improve the prompting instead of fine tuning. If your baseball summarization isn’t including the wining pitcher, then you should include that requirement into the prompt. Three big reasons to rl train:
Some critiera are not describable. What humans like is a fickle and difficult thing, and frankly it’s easier to just ask them for feedback and incorporate it directly.
We can train smaller models to perform just as good as bigger models, which is what our example is about.
Our models are stochastic, and don’t always produce the results we prompt for. RL training is a heavier handed way to influence behavior at the weights level.
Ok so why use LLM as a grader then? If we could get an LLM to grade, then surely we could have just incorporated that expertise into the prompts or the pre-training. Sadly no. In many cases expertise, or perhaps the style of expertise isn’t present or is washed out in the training set.
If we want our baseball summary to sound like a particular reporter that isn’t famous enough to be in the training data, we will need to fine tune2. The second is that if we want to rl train, it means we are dealing with tasks with which we cannot readily create objective evals for, which means human feedback is the only route we have to improvemenet.
The issue is humans are expensive. LLM as judges give us a cheaper and faster alternative. There are other reasons to use LLM as a judge in different scenarios, but these are the main ones for us3.
Base Model
Ok to start we will do supervised learning on a small transformer model. Let’s start by creating our dataset. It’s about 200 pairs of questions and answers that are mostly subjective:
eightBallDataset = [
{"question": "Will I be rich someday?", "answer": "Maybe"},
{"question": "Should I ask my crush out?", "answer": "Yes"},
{"question": "Am I going to pass my exam?", "answer": "No"},
...
{"question": "Will it rain tomorrow?", "answer": "Maybe"},
{"question": "Should I have dinner right now?", "answer": "Yes"},
{"question": "Should I go for a walk today?", "answer": "No"}
]We can the load that into a pytorch dataset for use in our training. All code generated with ChatGPT, with minor edits by me.
from torch.utils.data import DataLoader, Dataset
import json
# Sample dataset
class EightBallDataset(Dataset):
def __init__(self, data, vocab, max_length=10):
self.data = data # List of dictionaries with 'question' and 'answer' keys
self.vocab = vocab
self.max_length = max_length
self.label_map = {"Yes": 0, "No": 1, "Maybe": 2}
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
question = self.data[idx]['question']
label = self.data[idx]['answer']
encoded = [self.vocab.get(word, 1) for word in question.lower().split()][:self.max_length]
padding = [0] * (self.max_length - len(encoded))
return {
'input_ids': torch.tensor(encoded + padding, dtype=torch.long),
'label': torch.tensor(self.label_map[label], dtype=torch.long)
}
json_data = eightBallDataset
vocab = {word: idx for idx, word in enumerate(set(word for item in json_data for word in item['question'].lower().split()), start=2)}
vocab["<pad>"] = 0
vocab["<unk>"] = 1
dataset = EightBallDataset(json_data, vocab)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)Next we will create our simplified transformer. Here we will just use a single attention head.
# Simple transformer-like model
class SimpleTransformer(nn.Module):
def __init__(self, vocab_size, embed_dim=16, num_heads=2, hidden_dim=32, num_labels=3):
super(SimpleTransformer, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.attention = nn.MultiheadAttention(embed_dim, num_heads)
self.fc1 = nn.Linear(embed_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, num_labels)
self.relu = nn.ReLU()
def forward(self, input_ids):
embedded = self.embedding(input_ids).permute(1, 0, 2) # (seq_len, batch, embed_dim)
attn_output, _ = self.attention(embedded, embedded, embedded)
pooled = attn_output.mean(dim=0) # Mean pooling over sequence length
hidden = self.relu(self.fc1(pooled))
logits = self.fc2(hidden)
return logits
small_model = SimpleTransformer(vocab_size=len(vocab))Then we will create our training loop
def train_model(model, dataloader, epochs=10, lr=0.001):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
model.train()
for epoch in range(epochs):
for batch in dataloader:
optimizer.zero_grad()
input_ids, labels = batch['input_ids'].to(device), batch['label'].to(device)
logits = model(input_ids)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item():.4f}")
train_model(model, dataloader)and lastly we will try a prediction
def predict(model, question, vocab, max_length=10):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
encoded = [vocab.get(word, 1) for word in question.lower().split()][:max_length]
padding = [0] * (max_length - len(encoded))
input_tensor = torch.tensor([encoded + padding], dtype=torch.long).to(device)
with torch.no_grad():
logits = model(input_tensor)
prediction = torch.argmax(logits, dim=1).item()
label_map = {0: "Yes", 1: "No", 2: "Maybe"}
return label_map[prediction]
new_question = "Is water wet?"
answer = predict(model, new_question, vocab)
print(f"Question: {new_question}\nAnswer: {answer}")Question: Is water wet?
Answer: YesPerfect! We have a simple transformer that is essentially randomly spitting out yes, no, or maybe.
RL With Bigger Model
There is a lot that can be said about post training, and I’ll likely make a post another time diving into how complicated post training setups can get. For now though, we will keep our RL simple:

We will have our simple model output some completions. We would then have humans grade it, but here we will swap it with our more sophisticated model. In practice, we would likely make this a model focused on what style of output we want to produce, but for now just a more advanced model will do.
We will then have it remove the worst completions. Here we will remove any completion our best model isn’t strongly confident in a response for. If our best model is confident in an answer, we will align, and if it’s not we won’t. We will then take the loss generated from the difference between the larger model and smaller model, and back propogate that change through the small model.
def reinforce_model(small_model, large_model, tokenizer, learning_rate=2e-5, iterations=100, threshold=0.4):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
small_model.to(device)
small_model.train()
optimizer = optim.AdamW(small_model.parameters(), lr=learning_rate)
for _ in range(iterations):
question = reinforcement_8ball_questions[iteration % len(reinforcement_8ball_questions)]
small_model_answer = predict(small_model, question, tokenizer)
# Get response from a larger model
encoded = tokenizer(question, padding='max_length', truncation=True, max_length=10, return_tensors="pt")
input_ids = encoded['input_ids'].to(device)
attention_mask = encoded['attention_mask'].to(device)
with torch.no_grad():
output = large_model(input_ids, attention_mask=attention_mask)
probs = torch.softmax(output.logits, dim=1)
max_prob, large_model_answer = torch.max(probs, dim=1)
if max_prob.item() < threshold:
continue # Reject low-confidence responses
target_label = torch.tensor([large_model_answer.item()], dtype=torch.long).to(device)
# Perform a training step to align small model with large model
optimizer.zero_grad()
logits = small_model(input_ids, attention_mask)
loss = nn.CrossEntropyLoss()(logits, target_label)
loss.backward()
optimizer.step()
large_model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=3).to(torch.device("cuda" if torch.cuda.is_available() else "cpu"))
# Reinforcement learning
reinforce_model(small_model, large_model, tokenizer)Couple of notes. We use Bert with 3 label outputs for the classifier. It a better world we would use one of the large language models like ChatGPT, but I didn’t think this was worth the credits. Other than that our trainning loop is nearly the same, calculate a loss difference, back propogate it. It’s just that here our loss is calculated against our larger model.
And let’s see if there is a difference between before and after. We will run the model several times on an instance to get an average output logits. If our reinforcement learning is working, we should see a difference.
def collect_logits(model, question, tokenizer, runs=50):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
model.eval()
encoded = tokenizer(question, padding='max_length', truncation=True, max_length=10, return_tensors="pt")
input_ids = encoded['input_ids'].to(device)
attention_mask = encoded['attention_mask'].to(device)
logits_list = []
with torch.no_grad():
for _ in range(runs):
logits = model(input_ids, attention_mask)
logits_list.append(logits.cpu().numpy())
avg_logits = np.mean(logits_list, axis=0)
return avg_logitsjson_data = eightBallDataset
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
dataset = EightBallDataset(json_data, tokenizer)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
small_model = SimpleTransformer()
train_model(small_model, dataloader)
large_model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=3).to(torch.device("cuda" if torch.cuda.is_available() else "cpu"))
question = "Will I be successful?"
logits_before = collect_logits(small_model, question, tokenizer)
print("Logits before RL:", logits_before)
reinforce_model(small_model, large_model, tokenizer)
logits_after = collect_logits(small_model, question, tokenizer)
print("Logits after RL:", logits_after)Logits before RL: [[-0.8416683 -0.11846785 0.99824554]]
Logits after RL: [[-2.833587 -2.7987669 4.8489494]]And there you have it. Our model is much more likely to pick one consistent value of Maybe as a result of our reinforcement learning. We’ve gone from saying maybe randomly to saying maybe certainly! And presumably with a differently prompted model, we could have our smaller model skew towards whatever output we may want.
Conclusion
This is just a tast of what we can do with llm as a grader. By employing a second model that is specifically conditioned on a specific task, we can prompt our existing stronger or weaker model in the right direction.
Work Cited
Prometheus: The original ML as a grader
I’ll mention here that I actually looked through quite a few yes/no datasets like google’s boolq and FQSD to see if I could find a good dataset, but then I realized it doesn’t matter. There is a lot of active research to steering LLMs in different direcctions via RL like Nvidia’s HelpSteer dataset, but those are mainly around alignment to humans.
Yes, you can also one/few shot inside the context window. Yes, this can sometimes work, and is getting better with context window improvements. Fine tuning is still useful here though because we can minimize context window size for long running processes, and we can achieve an actual model we can furtther utilize if necessary.
Notable ones include: emphasizing that you have quality controls in place for your customer, and helping manage regressions due to data skew or model/prompt changes. There is a whole growing literature on this.