

evaluating llms
Large Language Models are inherently random. How can we objectively determine whether they are successful?

I’ve been thinking a lot about evaluating LLMs. As models get better, prompts become more complex, and the value to customers become a more important point of contention. Evals allow you to move toward success. These are related to public evals like those used in hugging face’s Open LLM Leaderboard, but focused on evaluating your specific business workflow. I wanted to just briefly discuss some of the ideas that are starting to form around evals, and then what to do with evals once you have them.
Making Evals
Why are we making evals?
Evals are basically tests for your llm workflows. The same question of why test a codebase can apply here: Because we have expectations of the behavior we want, and we want to codify those expectations to ensure that even as things change our system remains strong. If we decide to switch models, we experience data drift, or have a confused/angry customer to deal with, we need a clear set of aligned expectations to point to. The only issue here is that our system is now stochastic, meaning we can’t test for a specific expected behavior. Rather, we now have to allow for some level of variablity in our results. How we decide what variability is ok is at the heart of LLM evaluations.
What are we evaluating?
We are always evaluating one central question: Did the LLM complete the task as expected? This sounds much easier than it actually is. For some problems with clear objective solutions like the Math dataset this answer is simple since we can evaluate whether the llm produced the correct answer or not.1 For some tasks we may be able to define an objective criteria like with fixing bugs in code, but that might come with side effects we can’t easily test for like introducing new bugs, code quality problems, etc. Lastly, for more subjective tasks such as summarization, it’s much harder to define exactly what makes a good or bad summarization. This discussion will focus on how to create evaluations from these subjective problems, specifically summarization.
That is the objective we are optimizing for, but what are the levers we can test to see this change. The two biggest are the most obvious: the model and the prompt. We attach the results of these evals to those two characteristics. However, as more possibilities become available such as tools, longer inference reasoning, and web, we may have more potential a/b testing we can do to see the effects of quality.
We must also consider what data we use for our evaluations. Like traditional software tests we generally want a good spread of potential cases, as well as both happy path and sad path testing. If we are summarizing baseball games, we likely want a game that rained out, one with a no hitter, and other rare events we want to make sure we catch. We also likely just want a large mass of examples tests even if they are not unique simply to evaluate variance in responses, and attempt to capture subtle deviations in output that might be missed. But how can we actually evaluate this data?
Objective Criteria Evals
One of the simplest ways to get around the problem of subjective problems is to specify objective evaluations. These will never be fully comprehensive, but they can act as a canary for problems that emerge. Common objective criteria for summarization problems are:
Keywords: What specific words should be in the text? If you are summarizing a baseball game, we would likely expect the players names and the scores to be in the summarization. Note here it can be hard to check for inversions (not played and played will both pass if you only check for “played”)
Banned words: What specific words do we not want in the text? Maybe common hallucinations, or particular language we don’t desire. If summarizing a baseball game where a fight broke out, we likely wouldn’t want it to mention the fight.
Length: How long should the text output be? We can set bounds both minimum and maximum.
Ground Truth Comparison: If we have gold standard example to compare our generated content to, we can create evals centered around how similar our generated content is to this gold standard. There are a many possible answers here, but a few common ones are Levenshtein distance, Rouge Score, and Bleu score. These tests are generally better at seeing variance and drift then proving something about the actual text.
These are about as “Objective” as subjective problems tend to get. One can think of this more like regression testing, or smoke testing to just confirm we are in the correct ballpark of answer. We still require heavy levels of subjective testing to carry us through.
Subjective Criteria Evals
Subjective evals are just an evaluation you can’t create clear objective critiera for, usually resulting in many different opinions about what is correct. This is a rapidly growing field, so the ideas below are likely to change rapidly. I’ll also remind readers about the bitter lesson. You should spend time on these if you are attempt to create a canary for business applications, but don’t spend much on these if you are attempting to build great core ml models.
Human Feedback is a common tool to assess popularity. Usually this takes the form of a/b testing like when chat gpt will present two generated answers and ask users to select which they prefer. We might also include surveys with generated responses. This can either be of very simple yes/no form for key questions such as “was their a hallucination?”, “was their an issue with composition?”, “was the generated text helpful?”. We can also use Likert scale methods as another good way to get feedback, which asks users to place their happiness on a generally 5 point scale from Very Bad to Very Good. Overall, the generally vibe for human feedback seems to be minimially invasive, and focused on output quality.
LLM as an evaluator is also growing in popularity. The idea is to have a second llm judge the quality of the first LLM. This usually comes with a rubric that the LLM uses to score against. This criteria can be very subjective (i.e. “Is the text confident?”, “Does the text show x in a positive light?”, etc) to very objective (i.e. “Does the text mention x?”, “Does the text have a header?”, etc). I’m not as big of a fan of this method, though I’ve seen it used to success. My reasoning is that any criteria here should become explicit statements in the prompt, which tends to undercut how much this test acts as a signal.
The last is Expert Feedback. This is for situation where your content being summarized/generated is deeply technical, and the average person (aka you) cannot readily tell what is good or bad. This is more of a process to extract information to put into objective/subjective evals. A great example of this is AlignEval. You have an expert grade a large corpus of material, then from that feedback creates tests and update prompts. Iterate on this a few times, and you have heavily enriched feedback. You can then align an LLM evaluator to the point where your llm evaluator aligns closely to your expert feedback, thus allowing you infinite expert feedback evaluations. This is better in circumstances where your end customer is more versed in the particular subject.
All of this is attempting to objectify in some way that which is subjective. At the end of the day your number one metric is your own drive for excellence and your customer’s happiness.
Metrics
Metrics are a bit different then tests, but deserve to be mentioned here. Metrics are usually business specific expectations of the effect the content being generated drives. We also don’t generally have a pre-constructed correct answer, and thus can’t use our normal expectations drive test suite approach. If we are summarizing baseball games, we might track our click rate and our time on platform to see if the generated content is increasing engagement. If we are summarizing expense reports, we might look at the time required after generation or number of edits required by the person filing the report before they finalize. These are not explicitly about the generation, but are more focused on the effect the content has.
Note here as well this assumes a human in the loop. If you are fully automating a process, you may have to find some other way to create objective criteria around value. You can also use an LLM Evaluator as well here.
Code
Just for fun, I had ChatGPT whip up some code signifying the above. Here I use a baseball game summarization example, summarizing the game from a score sheet. Obviously this will very greatly depending on your db setup, backend, etc, but it creates a simple example of what we are talking about:
import openai
import rouge
from collections import defaultdict
# Placeholder function for calling OpenAI API
def generate_summary(score_sheet_text, prompt_id):
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Summarize the following baseball game score sheet:"},
{"role": "user", "content": score_sheet_text}
]
)
return response["choices"][0]["message"]["content"], prompt_id
# Objective evaluation
class ObjectiveEvaluator:
def __init__(self, ground_truth):
self.rouge_scorer = rouge.Rouge()
self.ground_truth = ground_truth
def evaluate(self, generated_summary):
scores = self.rouge_scorer.get_scores(generated_summary, self.ground_truth)
length = len(generated_summary.split())
keywords = ["home run", "strikeout", "inning"]
keyword_count = sum(1 for word in keywords if word in generated_summary.lower())
return {"rouge": scores, "length": length, "keyword_count": keyword_count}
# Subjective evaluation placeholder
class SubjectiveEvaluator:
def evaluate(self, generated_summary):
llm_score = 4.5 # Placeholder LLM grading
human_feedback = 4.2 # Placeholder human rating
expert_review = 4.8 # Placeholder expert rating
return {"llm_score": llm_score, "human_feedback": human_feedback, "expert_review": expert_review}
# Static performance metrics (CTR, time on platform)
class PerformanceMetrics:
def __init__(self):
self.metrics = defaultdict(lambda: {"CTR": 0, "time_on_platform": 0})
def update_metrics(self, prompt_id, ctr, time_on_platform):
self.metrics[prompt_id] = {"CTR": ctr, "time_on_platform": time_on_platform}
def get_metrics(self, prompt_id):
return self.metrics[prompt_id]
# Fake function to queue summary for expert review
def queue_for_expert_review(prompt_id, summary):
print(f"Summary with prompt_id {prompt_id} has been added to the expert review queue.")
# Example usage
def main():
score_sheet_text = "Sample baseball score sheet input."
ground_truth_summary = "Expected summary of the game."
# Generate summary
generated_summary, prompt_id = generate_summary(score_sheet_text, prompt_id="12345")
# Evaluate summary
objective_evaluator = ObjectiveEvaluator(ground_truth_summary)
subjective_evaluator = SubjectiveEvaluator()
performance_metrics = PerformanceMetrics()
objective_results = objective_evaluator.evaluate(generated_summary)
subjective_results = subjective_evaluator.evaluate(generated_summary)
# Update performance metrics
performance_metrics.update_metrics(prompt_id, ctr=0.12, time_on_platform=35)
performance_results = performance_metrics.get_metrics(prompt_id)
# Queue for expert review
queue_for_expert_review(prompt_id, generated_summary)
# Combine results
evaluation_results = {
"prompt_id": prompt_id,
"objective": objective_results,
"subjective": subjective_results,
"performance": performance_results
}
print(evaluation_results)
if __name__ == "__main__":
main()
We hit all of our key notes: objective criteria, subjective criteria, and have an expert review it for accuracy and relevance. We then combine this with hard business metrics to see how successful this prompt is for the business.
What do we do with evals?
Traditional test driven development generally doesn’t use tests in any particular way besides enshrining expectations in the system. By enshrining these expectations, we are able to move more confidently, we are able to increase our rate of development. LLM tests on the end have a lot more possibilities of what they can do. I’ll go over them now from least work intensive to most work intensive.
Help build Customer Confidence
At the lowest rung of the latter, we are just helping create confidence with the people that use our system. Most people won’t really care about the eval you use, only that they know the number good therefore life good. However, it’s still a clear showcase that you care about quality, and helps involve them in the process of creation. If we attempted to push our basbeall summarization bot onto some old professional baseball scouts, they likely would brush it off. But if they are involved in shaping the expertise of the system, and then have metrics to see how it’s performing, they are more likely to buy into it.
Change the Prompt
Prompting is the easiest way to get an llm to customize the kind of output. Usually this takes the form of:
Tell the llm what role it should be taking (i.e. you are a medical assistant)
Specifically stating what you want out of it (i.e. I want you to only reference material from the transcript, sound like Dr. Foo, and output a markdown table to accompany the description)
In context learning by providing examples in the prompt
This actually works surprisingly well for many circumstances. With a deep test suite, we can quickly get a sense of how much changes in the prompt affect our output. We can also at least a/b test these changes using our historical data as well to see how we are performing once we decide on a change.
Change the Model
Same as change the prompt. Here though I want to call out a classic adage in machine learning: “changing one thing changes everything”. While it’s easy to sit here and say we can just swap out models, the fact is that changing a model likely requires changing the prompt, likely requires changing your expectations. The hope is though that we can have a way to prove what model is performing better using our evals.
Change the Problem
It’s always important to ask the simple question: Am I solving the right problem? Not ever problem fits in an LLM sized box, and sometimes we have to reconsider whether or not LLMs are effective for getting to the root of the problem. Our evals can help tell us where we are missing the point.
Fine Tune the Model
Fine tuning is a post-training process where we train the model on a particular subset of data. The goal is change the actual weights of the model to better suite it to a particular task. We can use our evals to both help this process, and to evaluate it’s success in comparison to our base model.
In the past this was just done via a reward model with some kind of policy optimization like PPO. With newer models, more interest has centered around shoving LLMs into every section of post training. Specifically leveraging LLMs to create new synthetic data used for post training, and having an LLM help serve as the Reward model. Below iis an image of this process:
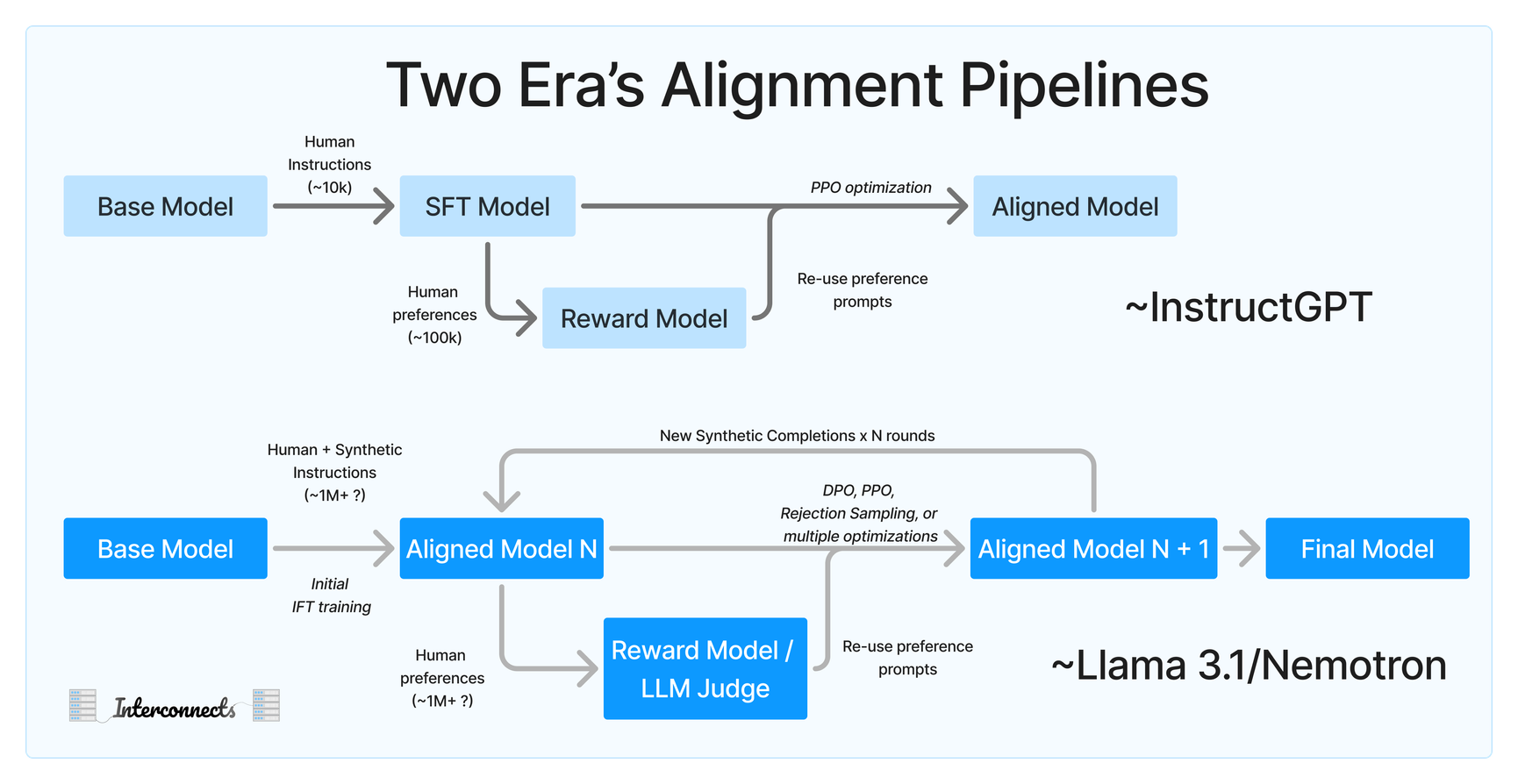
Let’s brieful discuss some of the common methods for aligning the model to a particular task via post training.
Train a Lora
Low rank adaptation is a process where instead of fine tuning large language models, we instead train a smaller model that we merge into the bigger model. This is done by a simple matrix trick. If our network is of size n*n, we instead train two matrices of size n*l and l*n where l is a value of our choosing. We can then matrix multiple the two together to create a model of size n * n, and then just add the weights/biases of the two models together. If l is small enough, this results in a signicantly smaller model that is easier to train. Since we only care about tailoring the content to our data we don’t need the entire model to get the results we want. For example, if our llm is a matrix of size 10x10 (100 values) we can train two vectors of size 10x1 1x10 (20 values). We thus only need to train a model 1/5 the size.
Train an Adapter
Similar to Lora, but instead of training a smaller section of weights to be added to the model, we instead simply train an entirely separate model. This is what Apple does for it’s Apple Intelligence. These are then placed as an additional layer inside the model as a bottleneck adapter. Note there are a myriad of ways this can also be used, and people are still actively exploring which is best.
Do full Post-Training Reinforcement learning
Lastly is a full post-training fine tune. This generally only makes sense if you are a massive company with a lot of money and data, so I won’t discuss it here. If you are interested, here is a good talk on post training, and here is a good youtube video on reinforcement learning for post training via PPO. Good luck!
Conclusion
I think we are hitting a point of LLMs really starting to disrupt workflows. Software ate the world, and now LLMs are the beginning of the end of the meal. Evals help us create a fly wheel that continues to eat more of the process, allowing us to get exponentially better as better models emerge with confidence.
Even further, this is making things better. Software engineers who didn’t use to write any documentation, can now have their entire docs page automatically updated with every new version. Doctor’s don’t have to spend the entire doctor’s appointment typing into an EHR. So much paper pushing is going away. It really does feel like white color knowledge work is changing. It use to be about executing, now it’s about taste and style. Work will be about creating the best policy for the LLM, and then managing AI as it handles the actual tedium of labor. Luckily you’ll have the evals to know your policy is correct!
Further Reading
Task-Specific LLM Evals that Do & Don't Work
What We’ve Learned From A Year of Building with LLMs
Note there is still the complication that the llm might produce other content not desired, for example if the answer requires just a number “3” it might add text such as “The answer is 3”, but using token library restrictions or reprompting we can get around this.