context faithfulness
“Context and memory play powerful roles in all the truly great meals in one’s life.” – Anthony Bourdain

With all the talk about large language model hallucinations, a growing area of concern in corporate AI roll outs is actually context faithfulness. I wanted to write a post about the current research into context faithfulness, and potential strategies to improve it.
Context Faithfulness
What do we mean by Context Faithfulness? Similar to the definition I thought up in the hallucinations post, context faithfulness is an LLM’s ability to adhere its answers to information presented in the context window. On the surface this seems straightforward. However, this definition presents a few different problems:
Counter Factual: How should an LLM respond if the information in the context window is counter to conventional fact?
Unrelated: How should an LLM respond if information in the context window is unrelated to a user’s query? Should it make a decision based on its own internal knowledge, say it doesn’t know, or provide some other response?
Inconsistent: If we provide multiple documents in the context window, how should the LLM respond if the answers provided are inconsistent with each other?
Plausibility: Should an LLM prioritize the provided context or its internal knowledge? In extraction tasks, like examining documents, context is the "source of truth." In evaluative tasks, like education, internal knowledge must override context to identify errors.
Scope: Should an LLM be allowed to make claims outside of the information provided by the context window, or should it stick to only information within the context? It may make generally true claims, but should it be allowed to make those claims if it can’t support them?
These different possibilities make it hard to conform general models to specific scenarios. Even worse, as models have gotten smarter via internal knowledge, their ability to consider external knowledge in the context window has actually gotten worse1. Managing these trade offs per task is a severe growing pain when getting LLMs into production workflow environments.
For pragmatic purposes, it’s generally considered that Long Form Question Answering (LFQA) is the standard means of testing whether an LLM can be faithful to its context. These are datasets where an LLM is presented with a document/question pair, and must produce an output consistent with a target answer2. This is consistent with many of the benchmarks we will discuss. Real world scenarios are more complicated, but this is close enough to have discussions on how faithful models are.
While we are discussing definitions, I’d like to include a definition on the theoretical side for textual entailment. Textual entailment is a natural language task determining whether the truth of one text fragment follows from another3. So, for example, the hypothesis “John is in Chicago” is entailed from the statements “John is in the park. The park is in Chicago.” This becomes much harder to discern as the text becomes larger, less clear in its claims, and with a hypothesis that is less directly derived. One can see though how textual entailment is related to our problem of contextual faithfulness. We seek to determine if generated text entails from the context window.
Evaluation Strategies
Let us now discuss different strategies for evaluating context faithfulness. To be frank, there doesn’t seem to be a lot of great ideas here.
The most obvious is to just use human judgement. This can be good in scenarios where you have available experts, or internal employees that can guide LLM evaluations. In practice, this usually takes the form of compiling a dataset of document/question/answer pairs created by the LLM, and then having a human grader either provide a yes/no or 1-5 score, followed by a critique comment. This feedback can then be either used to fine tune or improve prompts. In this same vein, LLM as a judge leverages a large language model in much the same way. It generates a score + comment to determine quality of generated output. For the most part, LLM as a judge appears to reasonably align with human reviewers for tasks4 though the results aren’t perfectly clear5. However, you’ll still need to calibrate the LLM as a grader carefully. In practical applications, I would use human reviewers to create a good sample dataset, then LLM as a grader for longer term monitoring + scaled evaluation. For research applications, it’s less clear when to use LLM as a grader vs human reviewers. I would suspect llm as a grader performs well given most LFQA datasets are not expert level tasks. LLM as a judge can also be great if you are using smaller models at scale, and want to confirm alignment between a smaller model and a larger judge model.
The next evaluation strategy is to breakdown the text into smaller more predictable chunks. FactScore6, which we’ve discussed before when I discussed claim edit distance, is one such method. This breaks text down into atomic facts, where each sentence is one measurable claim, and then compares those claims to ground truth data. By determining generated content by claim, you gain a clearer measurable metric of how correct an answer actually is. Mathematically, we represent FactScore of a model M to be the number of discrete claims contained within a generated text A that are supported by a ground source context of C for all generated responses.
Another method of breaking text down is Fact-Tuples7. This is similar to FactScore in that it breaks down text into smaller claims, but they structure their claims into tuples relating entities. For example, if the sentence is “John is in the park” that might become a tuple of (John, in, Park). We relate the two entities, John and Park, via a tuple of the form (entity, verb, entity). We can then compare the tuples to some source text to determin claim validity. If one is even more daring, you can then form an Abstract Meaning Representation (AMR) graph between entities using these tuples like FactGraph8. Getting back to Fact-Tuples, mathematically these are similar to FactScore. We generated tuples for the generated Text F_g as well as the ground truth text F_t. We then filter for only those claims that can be verified by the ground truth, and then compare tuple overlap.
So those are some of the methods. I’d also like to briefly mention a few popular benchmarks. The most notable I can find are Google’s recent Facts Grounding, Salesforce’s recently released FaithEval, and OpenAI’s TruthfulQA released a few years ago. There are many many more like FEQA, QAGS, and LFQA-e which are all released from various research groups inside of various universities. All of these are all essentially just LFQA datasets with broad non-domain specific document/question/answer pairs with LLM-as-a-grader or human judgement for evaluating generated text correctness. I’m sure there are more, but the space is still rapidly growing, and there isn’t a consensus target dataset or means of determining correctness.
Improvement Strategies
So how can we improve an LLMs ability to have context faithfulness? Let us discuss from the simplest to the most difficult.
Prompting
The most straightforward are prompting strategies. These are methods focused on changing the content of the context window to better communicate intent to the model. For example, one paper9 explored different methods on simply how the context, question, and options were presented. They structured it as an:
Opinion: Bob said, “{c}” Q: {q} in Bob’s opinion? Options: {o} A:
Attribution: {c} Q: {q} based on the given text? Options:{o} A:
Instruction: {Instruction} {c} Q: {q}? Options: {o} A:
And saw nearly a 20% improvement in context faithfulness as compared to the base prompt: “{c} Q: {q}? Options: {o} A:”. In addition, many of the hallucination detection methods I discussed can be helpful in improving prompt quality such as chain of thought, chain of verification, and self-critiquing techniques. Prompting is still in a phase of empirical testing, so it’s best to try things out with real world data.
Fine Tuning
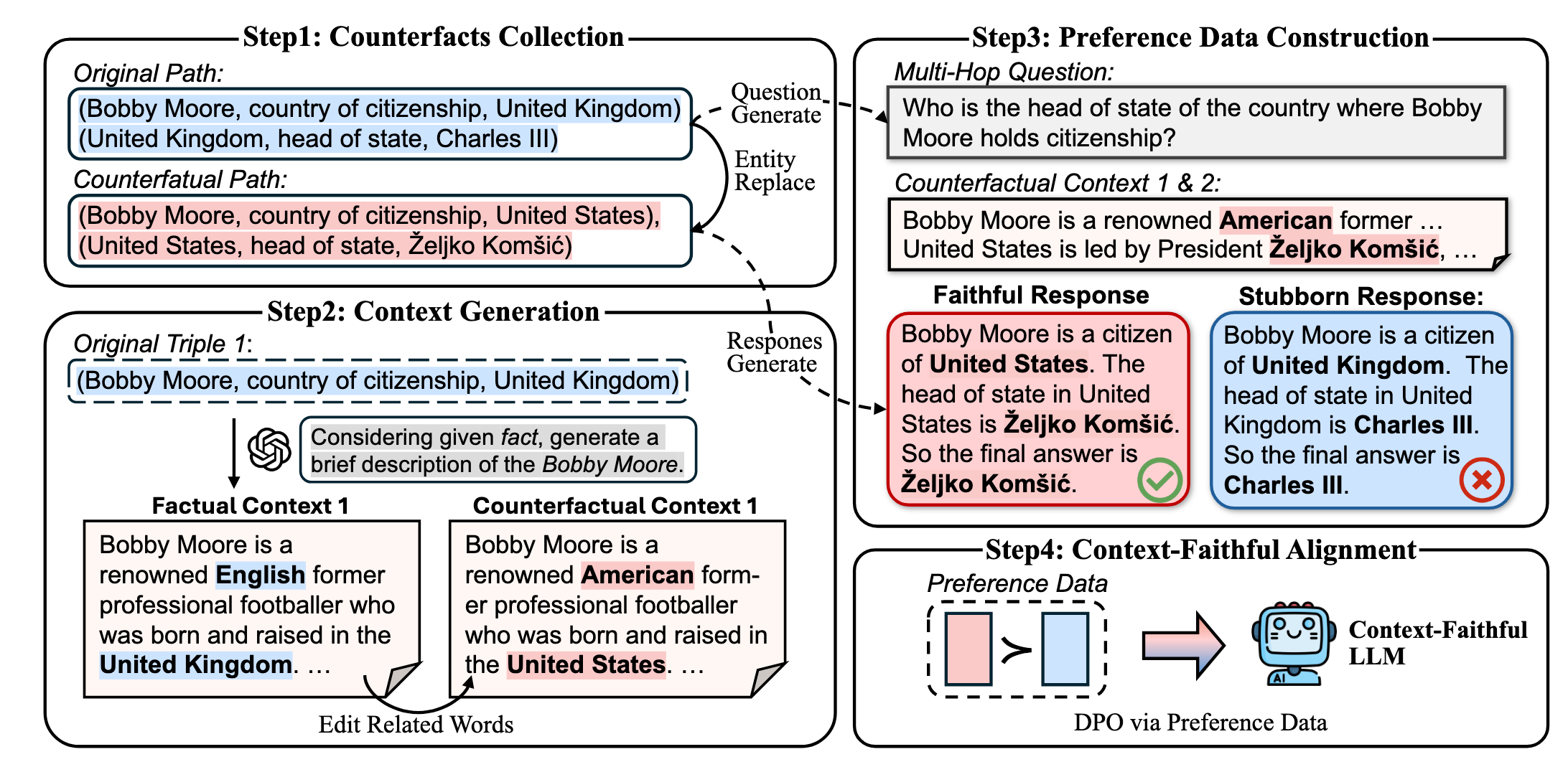
The next step up from prompting strategies is actual fine tuning of the model. The main paper I want to discuss here is Context-DPO10 which uses Direct Policy Optimization on counter factual contexts to improve context faithfulness. They implement this by first extracting fact tuples from wikipedia. Think (John, in, Park) from our earlier discussion of fact-tuples, but for conventionally established facts LLMs are likely to be trained on such as famous musicians or events. They then create a graph based on these tuples, and create questions that require multiple hops. So if we have (John, in, park) and (park, in, Chicago) a 2-hop question might be “What city is John in?”. We then augment these fact tuples to be incorrect. For example, we might change (park, in, Chicago) to (park, in, Los Angeles), and then generate context based on these incorrect tuples. This is important because we want to train the LLM to base it’s answer off what’s in the context window, even if it goes against the LLM’s internal knowledge. This creates a trade off between context faithfulness and internal knowledge that we can tune. They then generate a response based on the incorrect context window as well as the original correct context, and run DPO with preference for the incorrect, but context faithful generation.
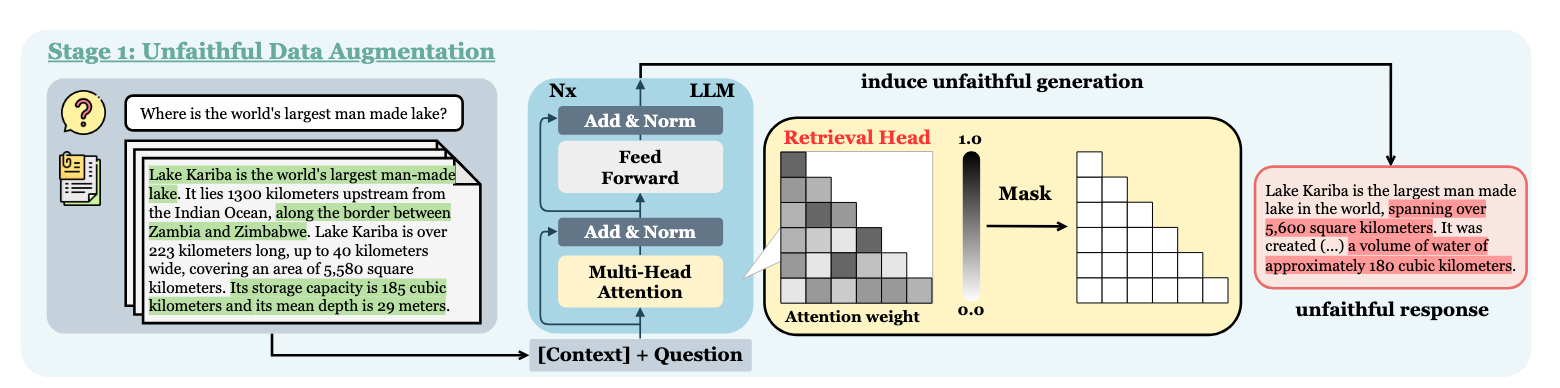
Another, heavier fine tuning paper focused on Retrieval Heads11. Retrieval Heads are attention heads inside the model whose specific purpose is to pull information from the context window. Retrieval Heads-Induced Optimization12 (RHIO) is a paper focused on leveraging these attention heads. They create a dataset of responses with these attention heads turned on to create faithful responses, and masked (turned off) to create unfaithful responses. They can then fine tune models off of these differences.
Decoding Methods
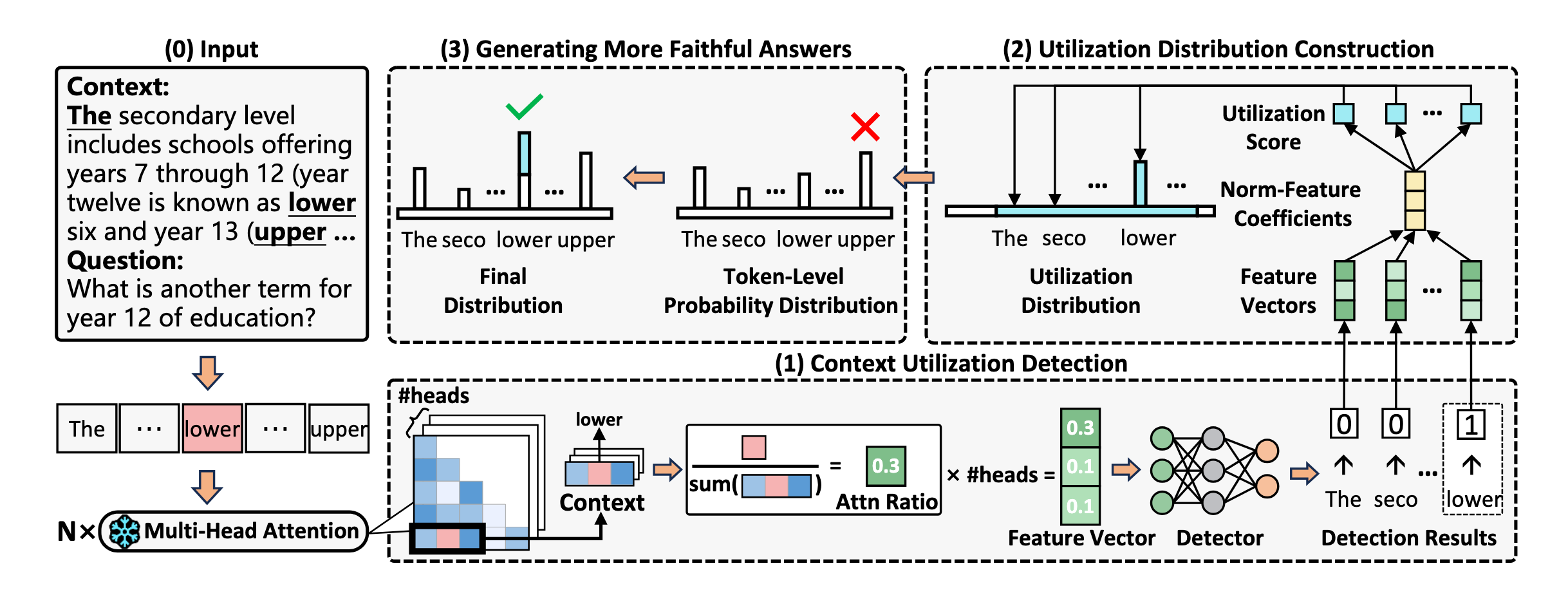
The next level up from fine-tuning are decoding methods. These are methods that changes the selection method given a set of logits in order to steer models towards specific tokens. For us these are tokens within the context window. Dynamic Attention-Guided Context Decoding13 (DAGCD) does this by identifying keywords inside the context window, determining how important they are for utilization in answer response, and then updating the final logit weights to bias towards those tokens.
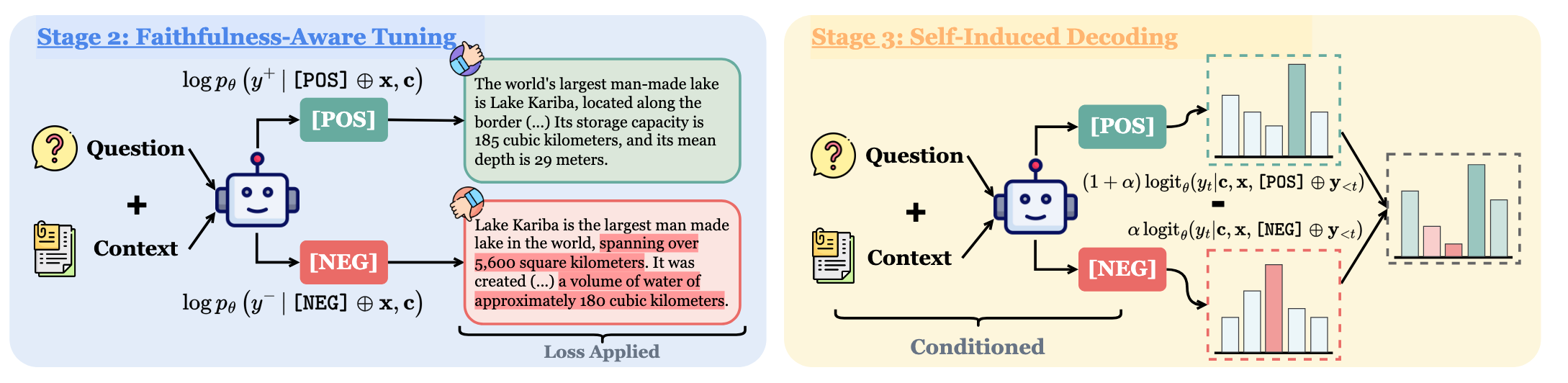
The RHIO paper discussed previously also has a decoding piece to it. They use special control tokens14, in the RHIO paper’s case they use [POS] and [NEG], to signal to the model to generate faithful and unfaithful responses so that they can do self-induced decoding, which is just another name for contrastive decoding where end logit probabilities are adjusted based on both positive and negative generations.
Knowledge Injection Methods
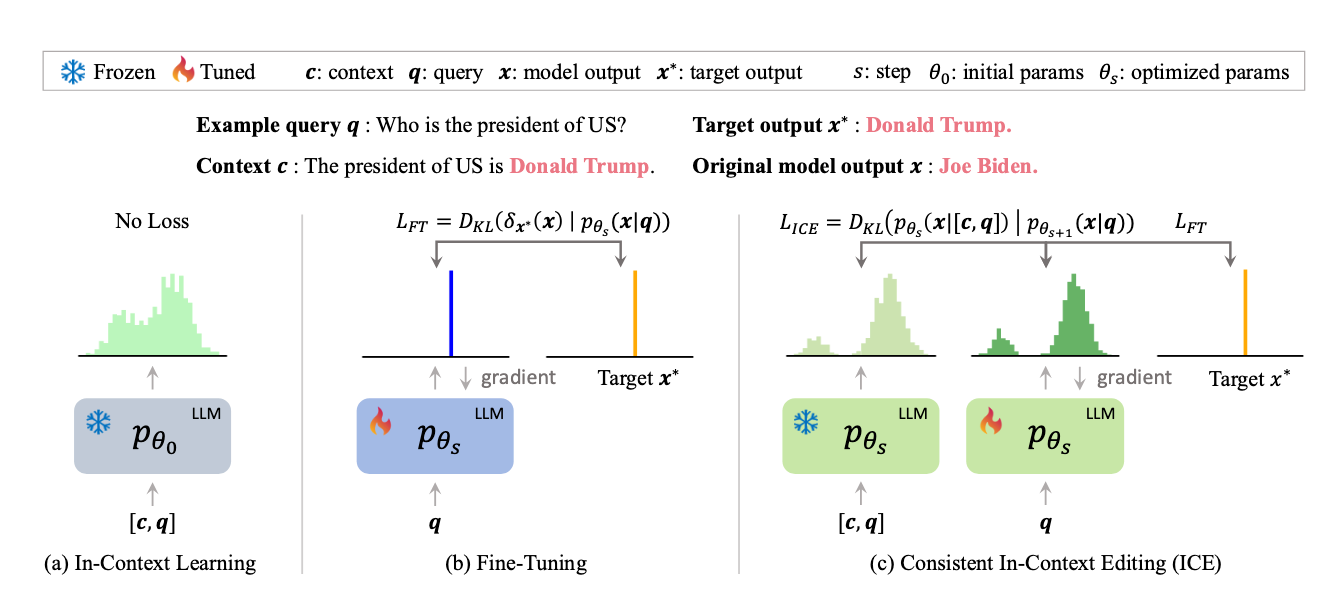
A related problem to context faithfulness in the world of large language models is how to effectively update them with new information. For example, the president may change from Joe Biden to Donald Trump. Models should somehow internalize this new knowledge to avoid out of date responses. While this isn’t the same as context faithfulness, some methods utilize the context window to help models train on new information. This has the potential side effect of encouraging the model to be more faithful to the information in the context window.
Papers like In-Context Editing15 add an additional loss term during fine tuning that encourages the model to have its answer be consistent with added context provided to the query. This encourages both new knowledge for existing queries, and can potentially help with context faithfulness. Other approaches like MeLLo16 use external knowledge to help provide new information. This can be seen as an extension of the context window, though this method doesn’t help as much with our faithfulness issue.
Conclusion
In my opinion, context faithfulness will be one of the biggest barriers to getting Large Language Models into production across the entire economy. People need to trust LLMs, and making sure the model says what you tell it to say is the most basic step in that direction. Obviously there are more issues here. We also need to consider what context to provide the model, and the model still needs to have strong internal knowledge to answer open ended queries.