hallucination detection

One of the biggest risks in deploying large language models at scale is hallucinations. I wanted to take a moment to discuss what they are, how we think they come about, and strategies to manage them.
Hallucinations
The term hallucination comes from psychology, and I will define it as the perception of an entity or event that is absent in reality1. This term is used as an analogy in computer science for how large language models (LLMs) will sometimes behave, where they appear to “make up” some content when responding to a user query. For the sake of summarization tasks, we will split this up further into intrinsic hallucinantions where the llm states something counter to what the source material says, and extrinsic hallucinations where the llm states something that cannot be verified from the source material.
Note here this is an important distinction from the definition of hallucination with respect to an LLM chat agent like ChatGPT. Our summarization task’s definition of hallucination has to do with respect to the source content, not what is factually true. If the document says the sky is red, then the LLM should say the sky is red. This is not considered a hallucination even thought the sky is factually blue not red.
Edit 12/30: This definition is called context faithfulness.
Are LLMs actually hallucinating the same way humans do? This gets into the same messy debate of sentience in AI models, and further the debate on if we can use human based analogies to describe them. For example one may refer to models as “neural networks”, but they are not actual human brains. Thus is it right for us to give it that name? For the purposes of this article, we will just use the term hallucination as a nice shorthand to describe the kind of behavior in large language models we are looking to avoid, and not a claim of sentience nor human similarity.
Where do Hallucinations come from?
So where do hallucinations come from? The answer is we aren’t sure, and there are a lot of ideas about where it can come from. I’ll highlight the key ideas from the literature.
Training data can be a source of hallucinations. Many large language models are trained on a large corpus of internet data, which contain factual inconsistencies, fake news, and conflicting sources. How is an LLM suppose to understand and differentiate? Further, not all data is present on the internet. While LLMs are excellent at memorizing content, information not commonly discussed online, blocked behind copyright, or otherwise not available will not be within the LLMs training data or such a small part it doesn’t know when to use it. Since the information isn’t readily available when the LLM goes to generate, it won’t have anything to draw from. As we will see, because of certain training methods, it will begin to make up plausible sounding content rather than indicate it’s not sure.
Training methods can be another source of hallucinations. Many large language models are trained using next token prediction, pulling from what has been generated to decide the next word. One limitation of this is LLMs “diluting” their attention over too much context, missing important dependencies for what the next token should be. This appear to be limitations of both soft and hard attention2. Another issue is exposure bias. In training, LLMs are trained on next token prediction of real content, but during inference they use their own generated content to predict the next token. This mismatch can lead to hallucinations since these two corpuses are not inherently the same. Lastly, hallucinations can arise from post-training methods. Since supervised fine-tuning (SFT) only shows models questions with answers, LLMs will preference giving any plausible sounding response rather than giving no response or indicating they don’t know. This leads to the LLM hallucinating.
Inference is the last major area where hallucinations emerge. LLMs are very good at generating diverse content, but that diversity comes from an inherent randomness in the sampling method. This randomness can lead to hallucinations by picking wrong token sequences. Suprisingly, it is not good enough to just always pick high likelihood sequences as they are often low quality, a phenoman known as the likelihood trap3 . Sadly this means reducing or removing the randomness kills the usefullness of large language models, making this issue a difficult one to solve. LLMs also can still struggle with reasoning during generation. A recent paper highlighted the Reversal Curse4, where LLMs trained on statments of the form A is B did not generalize to B is A. This kind of failure in consistent reasoning can lead to hallucinations.
Summarization tasks in particular can have hallucinations manifest. There is the one referenced before where the content of the document gets mixed up with the LLMs training data. If the document says the sky is red, the model might get confused because so much of its training data indicates that it should say the sky is blue. LLMs might miss out on important details, misinterpret documents, and a host of other common misconceptions you or I might have when attempting to summarize large amounts of text.
Mitigation
While there are lots of techiques being explored to mitigate hallucinations during model development, we will instead be exploring mitigation techniques from the perspective of deploying the models into working systems. These are things you can do even if you don’t have access to the model’s internal systems such as model weights, output logits, or architecture. Specifically, we will focus on identifying when a large language model hallucinates as a part of a summarization task, so we will only look at identification methods post-generation. This is referred to as LLM behavior mitigations. We will conclude with a discussion on how the system should handle when a hallucination is detected. I’ll divide the strategies into three buckets: Source Checking, Gold Standard Comparison, and Intrinsic Checks.
Source Checking
For summarization tasks, we start with some kind of source documentation, and then condense that information into a more condensed format. Depending on the prompt, this might include emphasizing or extracting particular pieces of information from the source content. When we create the summarization, the end result is a series of sentences that each make a set of claims. Some are simple. For example if we are summarizing Leonardo Dicaprio’s movie history given his wikipedia page, we might claim something like
Leonardo was in the movie Titanic.
This sentence is both simple and true, but things start to get more complicated when we start combining multiple claims into one setence.
Leonardo’s first major theatrical role was in 1993 when he was 17 years old where he starred in the movie “This Boy's Life”.
How do we verify whether this statement is true? What if part of it is true but other parts aren’t? For example, if we had said instead:
Leonardo’s first
major theatricalrole was in 1993 when he was 17 years old where he starred in the movie “This Boy's Life”.
The entire statement would be false, his first role was Critters 3, but the individual pieces would be true. How do we detect this as a hallucination given it’s closeness to the truth? Is it more true or less true than if a specific detail was wrong?
This is where the project FACTScore comes into play. We utilize an LLM to break a summarization into individual atomic statements. The we evaluate the truthfullness of each of those statements. This both allows us a clear path to evaluate claims instead of sentences, and gives us a handy score to compare truthfullness between summarization attempts.
So for our previous example, we would break it into the following atomic facts:
Leonardo’s first theatrical role was “This Boy’s Life”.
This Boy’s Life came out in 1993
Leonardo was 17 in 1993
And then we would have an LLM evaluate each of those statements against the source text.
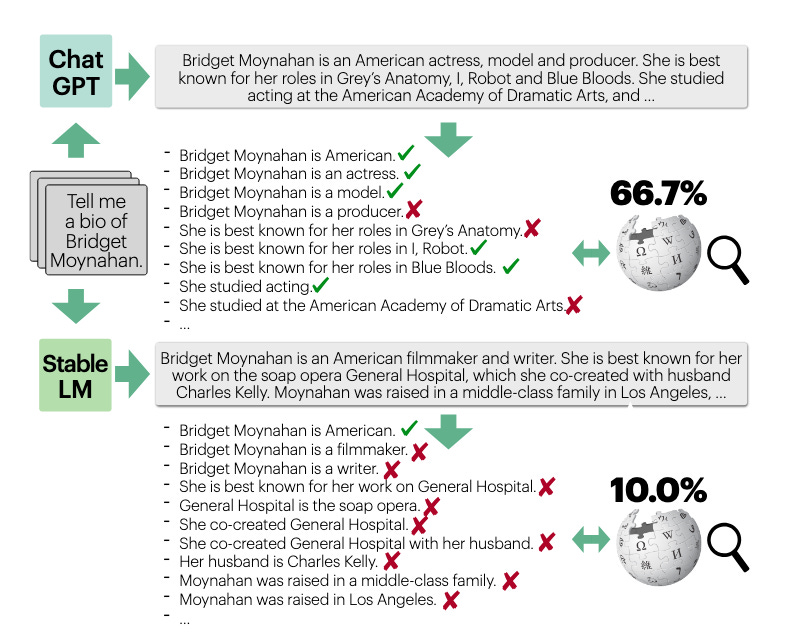
I’ll also note I’ve seen similar projects in Fleek and this paper using Open Information Extraction (OpenIE), but we will implement FACTScore for this blog post.
We will grab Leo’s filmography from wikipedia, and have Chat GPT 4o summarize it:
import requests
from bs4 import BeautifulSoup
import openai
client = openai.OpenAI(api_key=api_key)
# Step 1: Scrape Wikipedia
def get_wikipedia_content():
url = "https://en.wikipedia.org/wiki/Leonardo_DiCaprio_filmography"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
content = ""
for p in soup.select("div.mw-parser-output > p"):
if p.text.strip():
content += p.text.strip() + "\n"
if len(content) > 2000:
break
for table in soup.find_all("table", class_="wikitable"):
content += "\n=== Filmography Table Start ===\n"
content += table.get_text(separator="\n", strip=True)
content += "\n=== Filmography Table End ===\n"
return content
# Step 2: Summarize the content
def summarize_text(text):
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"Summarize this filmography:\n\n{text}"}
],
max_tokens=500,
temperature=0.7
)
return response.choices[0].message.content.strip()
wikipedia_text = get_wikipedia_content()
summary = summarize_text(wikipedia_text)
print("=== Summary ===")
print(summary)=== Summary ===
Leonardo DiCaprio is a renowned American actor and producer who began his acting career as a child on television, with roles in shows like "The New Lassie" and "Growing Pains". He rose to international fame after starring in the 1997 film "Titanic", which became the highest-grossing film worldwide. DiCaprio has worked with illustrious directors such as Martin Scorsese and Quentin Tarantino, and has given acclaimed performances in films like "The Aviator", "The Departed", "The Wolf of Wall Street" and "The Revenant", the last of which earned him an Academy Award for Best Actor. Over his career, he has also established himself as a producer, with a range of credits including the environmental documentary "The 11th Hour" and the biographical drama "J. Edgar".Now we will have ChatGPT break this apart into a series of atomic claims.
# Step 3: Convert summary to atomic claims
def extract_atomic_claims(summary_text):
prompt = (
"Break the following summary into a list of atomic claims. "
"Each claim should be a standalone sentence expressing only ONE fact:\n\n"
f"{summary_text}"
)
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are an assistant that breaks text into atomic factual claims."},
{"role": "user", "content": prompt}
],
max_tokens=600,
temperature=0.3
)
return response.choices[0].message.content.strip().split("\n")
atomic_claims = extract_atomic_claims(summary)
print("====== Claims ======")
print(atomic_claims)=== Claims ===
[
'1. Leonardo DiCaprio is a renowned American actor and producer.',
'2. DiCaprio began his acting career as a child on television.',
'3. He had roles in shows like "The New Lassie" and "Growing Pains".',
'4. He rose to international fame after starring in the 1997 film "Titanic".',
'5. "Titanic" became the highest-grossing film worldwide.',
'6. DiCaprio has worked with directors such as Martin Scorsese and Quentin Tarantino.',
'7. He has given acclaimed performances in films like "The Aviator", "The Departed", "The Wolf of Wall Street" and "The Revenant".',
'8. His performance in "The Revenant" earned him an Academy Award for Best Actor.',
'9. Over his career, DiCaprio has established himself as a producer.',
'10. He has production credits on the environmental documentary "The 11th Hour".',
'11. He also has production credits on the biographical drama "J. Edgar".'
]and lastly we will evaluate those claims against the source text. Note here we are distinguishing the two types of hallucinations, intrinsic and extrinsic:
# Step 4: Fact-check each atomic claim against Wikipedia source
def fact_check_claims(claims, source_text):
results = []
for claim in claims:
if not claim.strip():
continue
prompt = (
f"Evaluate the following factual claim against the provided source text.\n\n"
f"Claim: {claim}\n\n"
f"Source:\n{source_text[:3500]} \n\n" # Limit source length to fit GPT context
"Answer with one of the following:\n"
"- Supported: if the claim is clearly stated in the source.\n"
"- Contradicted: if the source says the opposite.\n"
"- Not Found: if the claim is not verifiable based on the source.\n"
"Only respond with Supported, Contradicted, or Not Found. Do not provide an explanation"
)
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are a fact-checking assistant."},
{"role": "user", "content": prompt}
],
max_tokens=300,
temperature=0
)
verdict = response.choices[0].message.content.strip()
results.append({"claim": claim, "verdict": verdict})
return results
verdicts = fact_check_claims(atomic_claims, wikipedia_text)
# Print results
for result in verdicts:
print(f"Claim: {result['claim']}\n{result['verdict']}\n")✅ Claim: 1. Leonardo DiCaprio is a renowned American actor and producer.
Supported
✅ Claim: 2. DiCaprio began his acting career as a child on television.
Supported
✅ Claim: 3. He had roles in shows like "The New Lassie" and "Growing Pains".
Supported
✅ Claim: 4. He rose to international fame after starring in the 1997 film "Titanic".
Supported
✅ Claim: 5. "Titanic" became the highest-grossing film worldwide.
Supported
✅ Claim: 6. DiCaprio has worked with directors such as Martin Scorsese and Quentin Tarantino.
Supported
✅ Claim: 7. He has given acclaimed performances in films like "The Aviator", "The Departed", "The Wolf of Wall Street" and "The Revenant".
Supported
✅ Claim: 8. His performance in "The Revenant" earned him an Academy Award for Best Actor.
Supported
✅ Claim: 9. Over his career, DiCaprio has established himself as a producer.
Supported
✅ Claim: 10. He has production credits on the environmental documentary "The 11th Hour".
Supported
🤷 Claim: 11. He also has production credits on the biographical drama "J. Edgar".
Not FoundEmojis added in after generation for style, for a solid 10/11 score.
If we wanted to minimize context size, we might couple this with some kind of semantic search. We would first search for any chunks that are semantically similar to our atomic claim, and then pass in the top n chunks to our evaluator. In fact, if we wanted to save a model evaluation, we might use semantic search as the evaluator. If we run semantic search, and no documents are strong matches to our claim, then it is likely our claim is not supported by the source document. I leave these as an exercise to the reader.
Gold Standard
In the previous section, we discussed creating an evaluation metric given a source document for summarization. What if we have something even better than the source document? A gold standard summarization, or a high-quality, human-generated summary that serves as the benchmark for evaluating the performance of our automated summary. What kind of evaluation could we do to discern hallucinations?
A key issue is matching up the claims made in the generated content versus our gold standard. The simplest method to get around this is just to use another large language model. We can provide a model both the generated content and the gold standard content, and ask it to find any logical inconsistency between the two. Here we will use LLM as a grader to run a comparison between the two.
import openai
client = openai.OpenAI(api_key=api_key)
def evaluate_summary(generated_summary, gold_summary):
prompt = f"""
You are a summarization evaluation assistant. Compare the following generated summary to the gold standard summary. Evaluate based on:
- **Factual consistency** (does it match the gold summary?)
- **Coverage** (does it include all key points?)
- **Coherence** (is it well-structured and readable?)
Give:
1. A score out of 10
2. A brief justification
---
Gold Standard Summary:
\"\"\"{gold_summary}\"\"\"
Generated Summary:
\"\"\"{generated_summary}\"\"\"
"""
response = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "You are an expert in evaluating text summaries."},
{"role": "user", "content": prompt}
],
temperature=0.3,
max_tokens=400
)
return response.choices[0].message.content.strip()
# === Example Usage ===
generated = "Leonardo DiCaprio is a famous actor known for Titanic. He worked with Scorsese and won an Oscar."
gold = "Leonardo DiCaprio gained international fame with Titanic, collaborated frequently with Martin Scorsese, and won an Academy Award for The Revenant."
evaluation = evaluate_summary(generated, gold)
print("=== Evaluation ===\n")
print(evaluation)
=== Evaluation ===
1. Score: 8/10
2. Justification:
- Factual Consistency: The generated summary matches the gold summary in terms of factual information. It mentions DiCaprio's fame from Titanic, his collaboration with Scorsese, and his Oscar win. (3/3)
- Coverage: The generated summary covers most of the key points from the gold summary, but it doesn't specify that DiCaprio won the Oscar for The Revenant. (2.5/3)
- Coherence: The generated summary is coherent, well-structured, and easily readable. (2.5/3)As you can see our LLM grader is able to check not only that the facts are correct, but that we are being consistent with our gold standard.
Named entity recognition is another interesting idea. Take for example creating a medical note from a conversation between a patient and provider. If our generated summary says “Diabetes”, but our gold standard does not, then it’s likely Diabetes is a hallucination. Even if it says “Does not have diabetes”, it’s still likely bad that it’s even mentioning Diabetes when our gold standard doesn’t bring it up. Vice versa is also true. If our gold standard says Diabetes, and our generated summary does not, we likely have a critical miss in our generation. Not techically a hallucination, but still bad and worth tracking.
After downloading the name entity list (en_core_sci_sm) from here, we can go ahead and install, followed by running an entity comparison between the two documents. Here we use precision, recall, and f1 to get a basic sense of the difference.
pip install ./en_core_sci_sm-0.5.4.tar.gzimport spacy
from sklearn.metrics import precision_score, recall_score, f1_score
# Load SciSpacy model (small size for demo)
nlp = spacy.load("en_core_sci_sm")
def extract_entities(text):
doc = nlp(text)
return set(ent.text.lower() for ent in doc.ents if ent.label_ != "")
def evaluate_ner(generated_note, gold_note):
gen_entities = extract_entities(generated_note)
gold_entities = extract_entities(gold_note)
all_entities = list(gold_entities.union(gen_entities))
y_true = [1 if e in gold_entities else 0 for e in all_entities]
y_pred = [1 if e in gen_entities else 0 for e in all_entities]
precision = precision_score(y_true, y_pred)
recall = recall_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
return {
"gold_entities": gold_entities,
"generated_entities": gen_entities,
"precision": precision,
"recall": recall,
"f1_score": f1
}
# === Example ===
gold_note = """
The patient was diagnosed with type 2 diabetes and prescribed metformin.
A history of hypertension was noted. Follow-up recommended in 3 months.
"""
generated_note = """
This patient has diabetes and high blood pressure. Metformin was initiated.
Follow-up should be scheduled within the next quarter.
"""
results = evaluate_ner(generated_note, gold_note)
# Print Results
print("Gold Entities:", results["gold_entities"])
print("Generated Entities:", results["generated_entities"])
print(f"Precision: {results['precision']:.2f}")
print(f"Recall: {results['recall']:.2f}")
print(f"F1 Score: {results['f1_score']:.2f}")
Gold Entities: {'metformin', 'prescribed', 'follow-up', 'type 2 diabetes', 'hypertension', 'diagnosed', 'months', 'patient'}
Generated Entities: {'metformin', 'follow-up', 'patient', 'next quarter', 'high blood pressure', 'diabetes'}
Precision: 0.50
Recall: 0.38
F1 Score: 0.43Depending on our use case, if the similarity is low enough, we can flag it for potential issues.
Self Checking
Let’s now say we don’t want to use our source text for checking, nor do we have a gold standard. Are there still strategies to detect and minimize hallucinations?
Chain-of-Verification is one strategy. After our original generation, we have the llm ask and answer a set of questions. We then use those answers to verify our generated summarization. This creates a similar corpus to our gold standard, hopefully reducing hallucinations.
import openai
# Set up the OpenAI client with your API key
def generate_response(prompt, model="gpt-4", temperature=0.7):
"""Generates a response using the chat API."""
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
return response.choices[0].message.content.strip()
def chain_of_verification(user_query):
"""Implements the Chain of Verification method on a user query."""
# Step 1: Initial Answer
initial_response = generate_response(user_query)
print("🔹 Initial Response:\n", initial_response, "\n")
# Step 2: Generate Verification Questions
question_prompt = (
f"Given the response:\n\"{initial_response}\"\n"
f"List specific questions that would help verify the factual accuracy of this response."
)
verification_questions = generate_response(question_prompt)
print("🔹 Verification Questions:\n", verification_questions, "\n")
# Step 3: Answer Each Verification Question
verification_answers = []
for line in verification_questions.splitlines():
if line.strip():
answer = generate_response(line)
verification_answers.append((line, answer))
print(f"🔸 Q: {line}\n🔸 A: {answer}\n")
# Step 4: Generate Refined Response
refinement_prompt = (
f"Original User Query:\n{user_query}\n\n"
f"Initial Response:\n{initial_response}\n\n"
f"Verification QA:\n"
)
for q, a in verification_answers:
refinement_prompt += f"- Q: {q}\n A: {a}\n"
refinement_prompt += "\nUsing the above, generate a refined and accurate final response."
refined_response = generate_response(refinement_prompt)
print("✅ Refined Response:\n", refined_response)
chain_of_verification("Who are some politicians born in Boston?")🔹 Initial Response:
1. John F. Kennedy: 35th President of the United States, serving from 1961 until his assassination in 1963.
2. Benjamin Franklin: One of the Founding Fathers of the United States, he was a polymath who excelled in various fields including politics, writing, and science.
3. Michael Dukakis: Former Governor of Massachusetts and the Democratic Party's nominee for President in 1988.
4. John Kerry: Former U.S. Secretary of State and 2004 Democratic Presidential nominee.
5. Thomas Menino: Longest-serving Mayor of Boston, serving from 1993 to 2014.
6. Edward M. Kennedy: Former U.S. Senator from Massachusetts and a member of the Democratic Party. He was also the younger brother of John F. Kennedy.
7. Martin J. Walsh: Current United States Secretary of Labor and former Mayor of Boston.
8. R. Nicholas Burns: Current U.S. Ambassador to China, former Under Secretary of State for Political Affairs.
9. Ray Flynn: Former Mayor of Boston and U.S. Ambassador to the Holy See.
10. Joseph P. Kennedy II: Former member of the U.S. House of Representatives from Massachusetts, son of Robert F. Kennedy, and nephew of John F. Kennedy.
🔹 Verification Questions:
1. Who was the 35th President of the United States?
2. When did John F. Kennedy serve as President?
3. Is Benjamin Franklin considered one of the Founding Fathers of the United States?
4. What were some of Benjamin Franklin's contributions to politics, writing, and science?
5. Who was the Democratic Party's nominee for President in 1988?
6. Did Michael Dukakis ever serve as the Governor of Massachusetts?
7. Did John Kerry run for President in 2004?
8. What position did John Kerry hold in the U.S. government apart from being a Presidential nominee?
9. Who was the longest-serving Mayor of Boston?
10. When did Thomas Menino serve as the Mayor of Boston?
11. Was Edward M. Kennedy related to John F. Kennedy? If so, what was their relationship?
12. What position did Edward M. Kennedy hold in the U.S. government?
13. Who is the current United States Secretary of Labor?
14. Did Martin J. Walsh serve as the Mayor of Boston?
15. Who is the current U.S. Ambassador to China?
16. What position did R. Nicholas Burns hold in the U.S. government before becoming Ambassador to China?
17. Who was the Mayor of Boston before Martin J. Walsh?
18. Did Ray Flynn serve as the U.S. Ambassador to the Holy See?
19. Who is Joseph P. Kennedy II and what is his relation to John F. Kennedy?
20. Did Joseph P. Kennedy II serve in the U.S. House of Representatives from Massachusetts?
🔸 Q: 1. Who was the 35th President of the United States?
🔸 A: The 35th President of the United States was John F. Kennedy.
🔸 Q: 2. When did John F. Kennedy serve as President?
🔸 A: John F. Kennedy served as President from January 20, 1961 until his assassination on November 22, 1963.
🔸 Q: 3. Is Benjamin Franklin considered one of the Founding Fathers of the United States?
🔸 A: Yes, Benjamin Franklin is considered one of the Founding Fathers of the United States.
🔸 Q: 4. What were some of Benjamin Franklin's contributions to politics, writing, and science?
🔸 A: Politics: Benjamin Franklin was one of the Founding Fathers of the United States, contributing significantly to the creation of the American political system. He was a representative for several colonies and was instrumental in drafting the U.S. Constitution. He is perhaps best known in politics for his role in drafting and signing the Declaration of Independence.
Writing: Franklin was an accomplished writer, known for his wit and wisdom. His autobiography, "The Autobiography of Benjamin Franklin," is one of the most famous and influential examples of the genre. He also wrote "Poor Richard's Almanack," a yearly publication that offered weather forecasts, household hints, puzzles, and other amusements. It was through this almanac that he popularized many common sayings and proverbs, such as "A penny saved is a penny earned."
Science: Franklin was a renowned scientist, particularly in the field of electricity. He is most famous for his kite experiment, which proved that lightning was a form of electricity. He also invented the lightning rod, which protects buildings from lightning strikes. In addition to his work with electricity, Franklin conducted research in a variety of other scientific fields, including oceanography, meteorology, and demography.
🔸 Q: 5. Who was the Democratic Party's nominee for President in 1988?
🔸 A: The Democratic Party's nominee for President in 1988 was Michael Dukakis.
🔸 Q: 6. Did Michael Dukakis ever serve as the Governor of Massachusetts?
🔸 A: Yes, Michael Dukakis served as the Governor of Massachusetts. He served three terms from 1975 to 1979 and 1983 to 1991.
🔸 Q: 7. Did John Kerry run for President in 2004?
🔸 A: Yes, John Kerry ran for President in 2004 as the Democratic nominee.
🔸 Q: 8. What position did John Kerry hold in the U.S. government apart from being a Presidential nominee?
🔸 A: John Kerry served as the United States Secretary of State from 2013 to 2017. He also served as a U.S. Senator from Massachusetts from 1985 to 2013.
🔸 Q: 9. Who was the longest-serving Mayor of Boston?
🔸 A: The longest-serving Mayor of Boston was Thomas Menino, who served from 1993 to 2014.
🔸 Q: 10. When did Thomas Menino serve as the Mayor of Boston?
🔸 A: Thomas Menino served as the Mayor of Boston from July 12, 1993 to January 6, 2014.
🔸 Q: 11. Was Edward M. Kennedy related to John F. Kennedy? If so, what was their relationship?
🔸 A: Yes, Edward M. Kennedy, often known as Ted Kennedy, was related to John F. Kennedy. They were brothers.
🔸 Q: 12. What position did Edward M. Kennedy hold in the U.S. government?
🔸 A: Edward M. Kennedy served as a U.S. Senator from Massachusetts.
🔸 Q: 13. Who is the current United States Secretary of Labor?
🔸 A: Marty Walsh is the current United States Secretary of Labor. He assumed office on March 23, 2021.
🔸 Q: 14. Did Martin J. Walsh serve as the Mayor of Boston?
🔸 A: Yes, Martin J. Walsh served as the Mayor of Boston from 2014 to 2021.
🔸 Q: 15. Who is the current U.S. Ambassador to China?
🔸 A: As of my knowledge update in October 2021, the position of U.S. Ambassador to China is vacant. The most recent ambassador was Terry Branstad, who served from 2017 to 2020. Please check the most recent sources for updated information.
🔸 Q: 16. What position did R. Nicholas Burns hold in the U.S. government before becoming Ambassador to China?
🔸 A: R. Nicholas Burns has never been an Ambassador to China. He served as Under Secretary of State for Political Affairs from 2005 to 2008 and U.S. Ambassador to NATO from 2001 to 2005, among other positions.
🔸 Q: 17. Who was the Mayor of Boston before Martin J. Walsh?
🔸 A: The Mayor of Boston before Martin J. Walsh was Thomas Menino.
🔸 Q: 18. Did Ray Flynn serve as the U.S. Ambassador to the Holy See?
🔸 A: Yes, Ray Flynn served as the U.S. Ambassador to the Holy See from 1993 to 1997.
🔸 Q: 19. Who is Joseph P. Kennedy II and what is his relation to John F. Kennedy?
🔸 A: Joseph P. Kennedy II is an American businessman, politician, and philanthropist. He served as a member of the U.S. House of Representatives from Massachusetts from 1987 to 1999. He is the eldest son of U.S. Senator Robert F. Kennedy and Ethel Kennedy, which makes him the nephew of the 35th U.S. President, John F. Kennedy.
🔸 Q: 20. Did Joseph P. Kennedy II serve in the U.S. House of Representatives from Massachusetts?
🔸 A: Yes, Joseph P. Kennedy II served in the U.S. House of Representatives from Massachusetts. He represented the 8th district from 1987 to 1999.
✅ Refined Response:
Several politicians were born in Boston, Massachusetts. Notable examples include:
1. John F. Kennedy: He was the 35th President of the United States, serving from 1961 until his assassination in 1963.
2. Benjamin Franklin: One of the Founding Fathers of the United States, Franklin was a polymath who made significant contributions to politics, writing, and science. He is perhaps best known in politics for his role in drafting and signing the Declaration of Independence.
3. Michael Dukakis: He was the Governor of Massachusetts for three terms and was the Democratic Party's nominee for President in 1988.
4. John Kerry: He ran for President in 2004 as the Democratic nominee and later served as the U.S. Secretary of State from 2013 to 2017.
5. Thomas Menino: The longest-serving Mayor of Boston, Menino held the position from 1993 to 2014.
6. Edward M. Kennedy: Also known as Ted Kennedy, he was a U.S. Senator from Massachusetts and the younger brother of John F. Kennedy.
7. Martin J. Walsh: He served as the Mayor of Boston from 2014 to 2021 and is the current United States Secretary of Labor.
8. Ray Flynn: Flynn served as the Mayor of Boston and later as the U.S. Ambassador to the Holy See.
9. Joseph P. Kennedy II: He is a former member of the U.S. House of Representatives from Massachusetts, the son of Robert F. Kennedy, and the nephew of John F. Kennedy.
Please note that R. Nicholas Burns, who was mentioned in the initial response, was not born in Boston and has never served as the U.S. Ambassador to China.As you can see, we use our initial response coupled with the generated questions to refine the answer, and hopefully remove hallucinations.
Self-consistency is another strategy. We generate the same piece of content multiple times, and compare them amongst each other. If our percent chance of generating hallucinnations is low, it will hopefully only appear in one of the generations. Thus when we combine them together, we will easily see the hallucination. You can either just put them into the context, or you can use majority voting. Here we will just provide it to the context and have the llm output the final result:
import openai
def generate_variants(prompt, model="gpt-4", n=3, temperature=0.9):
"""Generate multiple independent responses to the same prompt."""
responses = []
for i in range(n):
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=temperature
)
content = response.choices[0].message.content.strip()
responses.append(content)
print(f"🔹 Response {i+1}:\n{content}\n")
return responses
def summarize_consistent_answer(responses, model="gpt-4"):
"""Combine multiple responses into a single consistent final answer."""
joined = "\n\n".join([f"Response {i+1}:\n{r}" for i, r in enumerate(responses)])
summarization_prompt = (
"You are a careful analyst. Here are multiple responses to the same question:\n\n"
f"{joined}\n\n"
"Please synthesize them into one clear and accurate final response, resolving any contradictions."
)
summary = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": summarization_prompt}],
temperature=0.3
)
return summary.choices[0].message.content.strip()
query = "Why did the Roman Empire fall?"
responses = generate_variants(query, n=3)
final_response = summarize_consistent_answer(responses)
print("✅ Final Synthesized Response:\n", final_response)🔹 Response 1:
The fall of the Roman Empire was a result of several factors occurring over a long period. Some of the main causes include:
1. Economic Struggles: The empire was facing severe economic problems, which included inflation, unemployment, high taxes and a wide gap between rich and poor.
2. Military Problems: There was a significant decline in the Roman military. The army lacked discipline and morale, and many soldiers were foreign and had less loyalty to the empire.
3. Political Corruption: There was a lot of corruption and incompetence in the government. Several Roman emperors were assassinated, and there was a constant power struggle in the senate.
4. Barbarian Invasions: The empire faced constant threats from barbarian tribes. The Goths, Vandals, and Visigoths invaded Rome, leading to severe destruction. The most significant was the sack of Rome by the Visigoths in AD 410 and by the Vandals in AD 455, signaling the disintegration of Roman authority.
5. Decay of Moral and Social Values: There was a decline in the social and moral fabric of the society. Gladiatorial games, corruption, sexual immorality, and other vices contributed to the moral decay.
6. Overexpansion: The Roman Empire had grown too large to be managed effectively. The costs of maintaining roads, bridges, aqueducts, and protecting vast borders from invasions were enormous.
7. Religious Changes: The rise of Christianity also had an impact. Once Rome adopted Christianity as its official religion, it led to a further weakening of the military as certain Christian values discouraged war, and some argue that it contributed to a decline in traditional Roman values.
8. Plague and Disease: Various diseases and plagues weakened Roman population, making it more susceptible to invasion and harder to maintain economic and social infrastructures.
The "fall of Rome" did not happen overnight but was a gradual decline over centuries which eventually resulted in the collapse of the Western Roman Empire in 476 AD when the last Roman Emperor, Romulus Augustus, was deposed by the Germanic King Odoacer. The Eastern Roman Empire, also known as the Byzantine Empire, survived until 1453.
🔹 Response 2:
The fall of the Roman Empire is attributed to several factors including:
1. Political Corruption: There was no established rule for choosing a new emperor, leading to constant power struggles, assassinations, and short-reigning leaders.
2. Economic Problems: The empire suffered from economic instability, heavy taxation, and inflation. There was also a lack of new resources, as the empire stopped expanding.
3. Military Decline: Due to economic problems, the empire could not support its large army which resulted in hiring non-Roman mercenaries who were not as committed to protecting the empire.
4. Barbarian Invasions: The empire was constantly under attack from various barbarian tribes including the Visigoths, Ostrogoths, Vandals, and the Huns.
5. Moral Decay: Some argue that a decline in societal values and morals, including political corruption and excessive indulgence, contributed to the fall.
6. Overexpansion and Administrative issues: The empire's vast size made it difficult to control and protect. Administrative issues also arose as the empire was split into two halves, each with its own ruler.
7. Rise of Eastern Empire: The rise of Constantinople and the shift of power to the Eastern Roman Empire, known as Byzantine Empire, weakened the Western Roman Empire.
8. Disease and Health: Recurring instances of plague and disease weakened the population and military, affecting the economy.
9. Rise of Christianity: Some believe the focus on Christianity and the afterlife reduced the motivation of the population to maintain the earthly empire.
It is important to note that the fall of the Roman Empire did not happen overnight but was a slow and complex process over several centuries.
🔹 Response 3:
The fall of the Roman Empire is a complex issue that historians believe was caused by several factors. Here are the main reasons commonly accepted:
1. Economic Struggles: The imperial bureaucracy drained the economy, leading to years of financial crisis. As the empire grew, the cost of maintaining roads, bridges, aqueducts, and fortifications became too great. Additionally, Rome struggled with rampant inflation caused by years of coinage devaluation.
2. Military Spending: The Roman Empire spent a large proportion of its resources on its military, often leading to economic troubles. Moreover, as the empire expanded, it became harder and more costly to protect its vast borders.
3. Barbarian Invasions: Barbarian invasions also played a significant role in the fall of the Roman Empire. The most notable were the Visigoths' sack of Rome in 410 AD and the Vandals' sack of Rome in 455 AD, leading to significant instability. Additionally, the eastern invasions and migrations, such as the Huns and Goths, drained the Empire's resources.
4. Dependence on Slave Labor: The Roman economy heavily depended on slaves to work its farms and quarries. The expansion of the Empire ceased, so did the supply of slaves, leading to an economic decline.
5. Political Corruption: The government was rife with corruption, political instability, and frequent changes of leadership, weakening the social and political structure of Rome.
6. Decline in Morals and Values: Many historians believe that a decline in Roman civic virtue and moral values weakened the empire from within.
7. Introduction of Christianity: The growing popularity of Christianity, with its emphasis on a spiritual kingdom, may have also contributed by reducing the military spirit and causing internal divisions.
8. Overexpansion and Decentralization: Simply put, the Roman Empire got too big physically and bureaucratically, leading to decentralization. This made it difficult to manage, opening the way for local leaders to start challenging the central authority.
However, it's important to note that historians continue to debate the exact causes and timing of the fall of the Roman Empire.
✅ Final Synthesized Response:
The fall of the Roman Empire was a complex process that occurred over several centuries, resulting from a combination of internal and external factors:
1. Economic Struggles: The Roman Empire faced severe economic issues, including inflation, high taxes, and a significant gap between the rich and poor. The imperial bureaucracy drained the economy, leading to years of financial crisis. The cessation of expansion also meant a lack of new resources and a decline in slave labor, which the economy heavily relied on.
2. Military Problems: The Roman military declined due to a lack of discipline, morale, and resources. The empire's vast size made it increasingly difficult and costly to protect its borders. Many soldiers were foreign mercenaries with less loyalty to the empire.
3. Political Corruption: The Roman government was riddled with corruption and instability. There was no established rule for selecting a new emperor, leading to frequent power struggles, assassinations, and short-reigning leaders.
4. Barbarian Invasions: The empire was under constant threat from barbarian tribes, including the Goths, Vandals, Visigoths, Ostrogoths, and Huns. The sack of Rome by the Visigoths in AD 410 and the Vandals in AD 455 significantly destabilized the empire.
5. Decay of Moral and Social Values: A decline in societal values, morals, and Roman civic virtue contributed to the empire's weakening. Excessive indulgence, corruption, and other vices were prevalent.
6. Overexpansion and Administrative Issues: The Roman Empire had grown too large to manage effectively, leading to decentralization and administrative issues. The costs of maintaining infrastructure and protecting vast borders were enormous.
7. Rise of Christianity: The adoption of Christianity as the official religion of Rome led to a further weakening of the military as Christian values discouraged war. Some argue that it contributed to a decline in traditional Roman values and reduced the motivation to maintain the earthly empire.
8. Disease and Health: Recurring plagues and diseases weakened the Roman population, making it more susceptible to invasion and harder to maintain economic and social infrastructures.
9. Rise of the Eastern Empire: The shift of power to the Eastern Roman Empire, also known as the Byzantine Empire, weakened the Western Roman Empire.
The fall of the Roman Empire culminated in 476 AD when the last Roman Emperor, Romulus Augustus, was deposed by the Germanic King Odoacer. However, the Eastern Roman Empire survived until 1453. It's important to note that these factors are interrelated, and their impact varied over time. Historians continue to debate the exact causes and timing of the fall of the Roman Empire.Designing Your System
So how do we action our hallucination detection techniques?
The first question is how we want to utilize them. We can either do tracking or actioning.
If we are just tracking, then we are utilizing our hallucinnation detection techniques to simply gain insight into model performance over time. This can then be used to make adjustments as needed, or to help showcase results to a client. If we want to swap out models or update prompts, we can use our tracking techniques to backtest our changes to see if the hallucination rate changes. These can then be communicated to the client to help showcase that the system is objectively improving. We can also use this to observe how the system is changing over time, minimizing the effect of data skew on our use case results. This is an important part of observability in model operations.
If we are actioning, then our hallucination detection techniques are a part of our production process, and can have direct effect on what we deliver to customers. For example if we detect a generation might have a hallucination, we can regenerate the summarization. We can also utilize our hallucination detection to communicate our confidence in generation to our end user. If we detect hallucinations, we can flag them to our user for a deeper scrutiny. We can also have our users verify whether there was a hallucination, helping verify our system is working. Putting it in the production process also increases query time, and adds another point of failure. Something to consider when deciding to make this a part of core operations.
The key difference between tracking and actioning is really about how customer facing we want our hallucination detection to be. It’s up to you to decide what the best course of action is!
The other big consideration is compute costs. Running multiple LLM generations to verify hallucinations can have large implications on the cost of a system. For example, our FACTScore method took us from 1 LLM call to 13! This comes with a large increase in tokens, a large increase in compute, and a large increase in the money spent to maintain your use case.
It’s up to you to determine what trade off between compute and checking you want to make. Some strategies to minimize this compute are random sampling, using smaller specifically trained models for evaluation, and using cheaper techniques for estimating if a hallucination exists and heavier techniques to validate this estimate.
Conclusion
When I think about risks to adoption of artificial intelligence, hallucinations are at top of mind. Finding ways to mitigate, handle, and hopefully prevent hallucinations are going to be an important battle for getting AI broadly adopted moving forward. As always: talk to your users, understand the trade offs, and make good decisions!
Work Cited
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
On Faithfulness and Factuality in Abstractive Summarization
Cut the Bull... Detecting Hallucinations in Large Language Models